
In one of the learning platforms that I joined. There are only audio lessons. For me, if it’s only audio and has a long duration, it’s easy to lose focus or be distracted. According to that problem, I recall that I can use WhisperCPP with a large model and Python to create the transcription. The audio uses a mix of Indonesian and Arabic languages.
The program flow will be like this
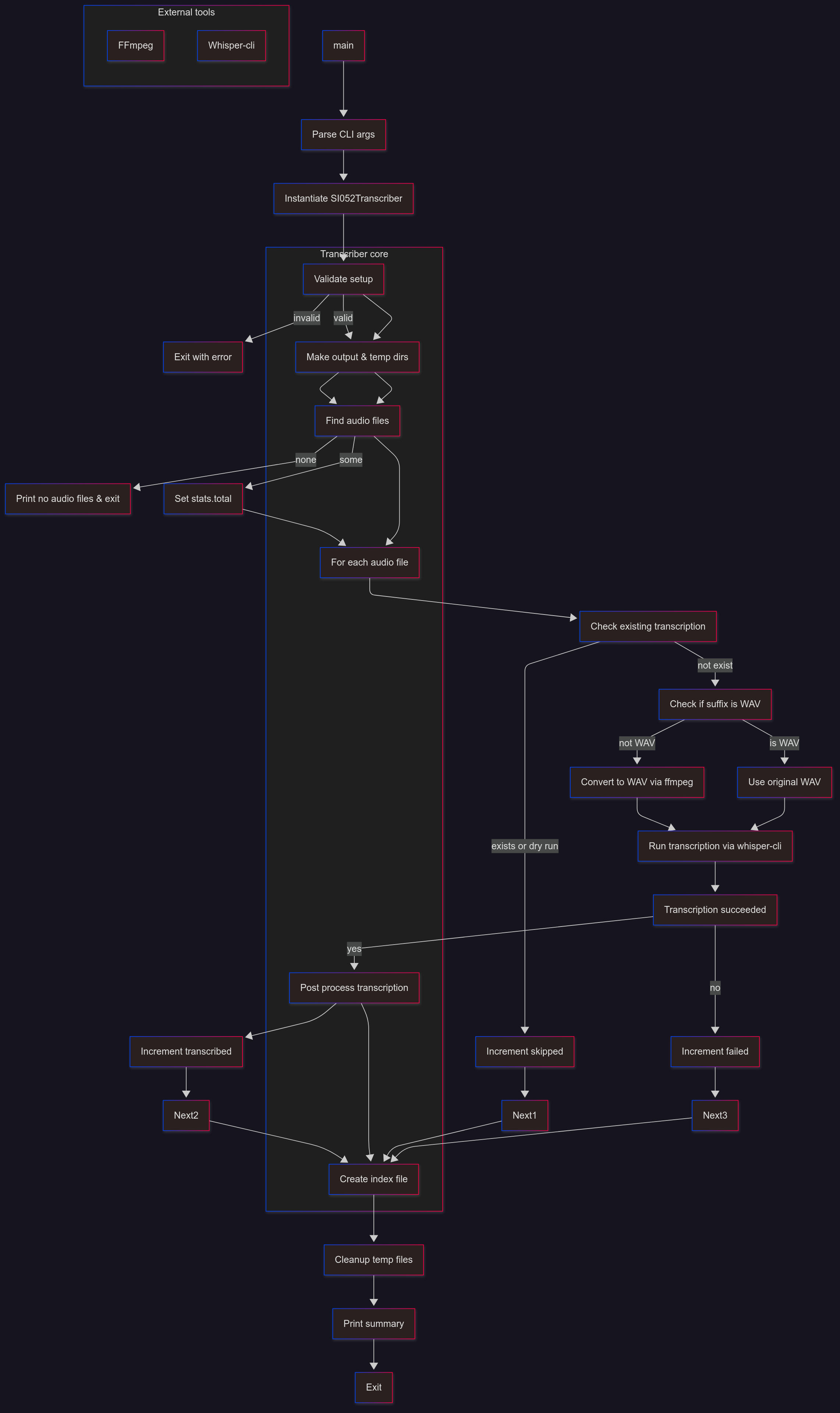
1. Initialization
- The process begins with external tools:
- FFmpeg → for audio format conversion
- Whisper-CLI → for transcription
- Steps:
- Run
main - Parse CLI arguments
- Instantiate the SI052Transcriber object
- Run
2. Setup Phase
- The transcriber performs setup tasks:
- Validate setup
- If invalid → Exit with error
- Create output and temporary directories
- Find audio files in the input folder
- If none found → Print no audio files & exit
- If found → Save count in
stats.total
- Validate setup
3. Processing Audio Files
For each audio file, the following steps are performed:
3.1 Check Existing Transcription
- If transcription already exists:
- Increment skipped
- Move to the next file
3.2 Validate Audio Format
- If not WAV → Convert to WAV via FFmpeg
- If WAV → Use original file
3.3 Transcription
- Run Whisper-CLI to transcribe audio
- If transcription fails:
- Increment failed
- If transcription succeeds:
- Proceed to post-processing
3.4 Post-Processing
- Perform post-process transcription (cleanup & formatting)
- Save the transcript in multiple formats
- Increment transcribed count
4. Finalization
After all files are processed:
- Create an index file (summary of outputs)
- Cleanup temporary files
- Print summary statistics:
- Total files
- Transcribed
- Skipped
- Failed
- Exit gracefully
So, in this case, I download all of the available audio, and I also use a separate script for that. After that, I place it into one folder for all of the downloaded audio.
The next step is creating a Python script to list all of the audio files inside the folder, and distinguish the true audio MP3 files and the wrong ones (in my case, I download all of them, and some of them are pdfs files that I give .mp3 extensions). The result will be a list of all the true audio files, then I convert the MP3 files into the .wav extension using ffmpeg. This is where ffmpeg comes in handy; I don’t need to convert it manually one by one. After the files became .wav extensions, I used whisper cpp and downloaded the large v3 model from this Hugging Face (https://huggingface.co/ggerganov/whisper.cpp).

After that started to transcribe one by one. The result will be .txt files and .srt files if, in the near future, I want to use the .srt files.
The transcribing process looks like this

Surprisingly, for the CPU usage, it’s only taken a little resource on my MacBook Pro M1 Pro.
And this is the file’s audio and the result
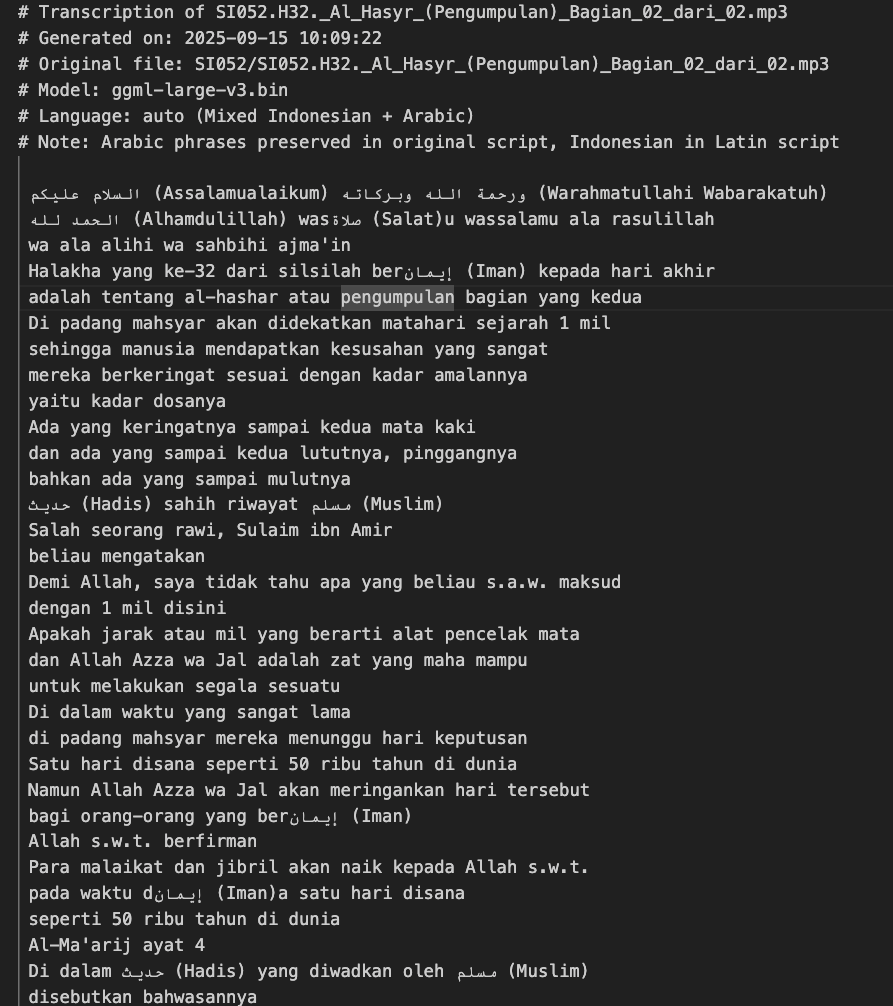
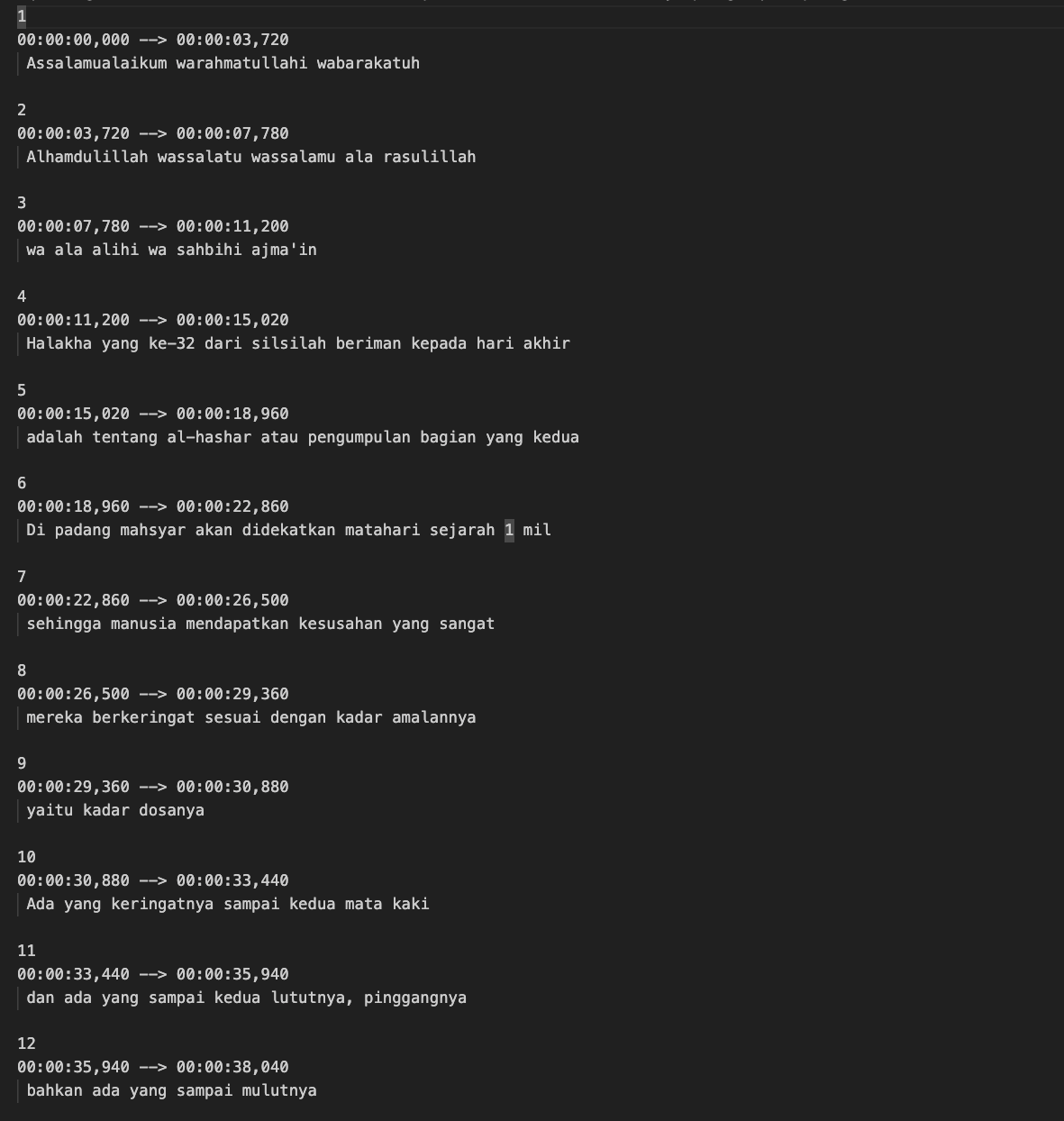
The result example for the .txt files looks like this. Although it’s not perfect but at least it’s better than listening without reading.
Github Repository https://github.com/sipamungkas/convert-and-transcribe-audio-ffmpeg-and-whisper-cpp
Finally
Thank you for reading this far! So, what’s your opinion about this progress? Do you have any suggestions or any ideas? What will you create in your next project that will help you in your daily use?
The one who writes does not necessarily possess more knowledge than the one who reads.
Tidaklah yang menulis lebih berilmu daripada yang membaca.